Hello world! My name is Frederick, one of the GSoC interns who will be contributing to WordPress migration Moving the code, database and media files for a website site from one server to another. Most typically done when changing hosting companies. features this summer.
A proud Canadian who grew up in Toronto and its suburbs, I am currently a bioengineering undergraduate at the University of Pennsylvania in Philadelphia, with hopes of working in the clinical and public health roles of a physician. The connection to coding might seem tenuous, but I am a firm believer in pursuing passions, despite how incongruous they may seem. As I wrote in my application, WordPress has offered me much in the way of community and inspiration, and I hope to gain better insight into my own aspirations through this internship.
Like many in the community, my involvement with WordPress has included some plugins, and sites developed for work and student organizations. Although I’ve worked on two separate open source Open Source denotes software for which the original source code is made freely available and may be redistributed and modified. Open Source **must be** delivered via a licensing model, see GPL. PHP The web scripting language in which WordPress is primarily architected. WordPress requires PHP 7.4 or higher projects, this is the first opportunity I’ve had to contribute to something that can reach so many people; indeed, the past Ten Good Years have yielded not only a collection of lines of code Lines of code. This is sometimes used as a poor metric for developer productivity, but can also have other uses., but a huge and intensely active ecosystem of developers, designers, and users. To have the chance, even for 3 short months, to be a part of it, is both exhilarating and terrifying at the same time!
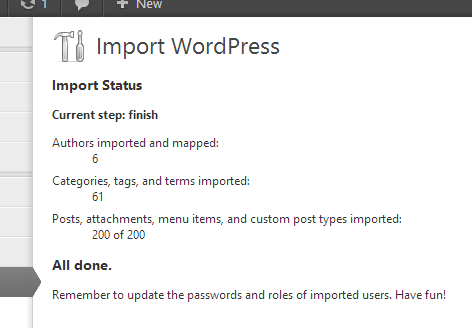
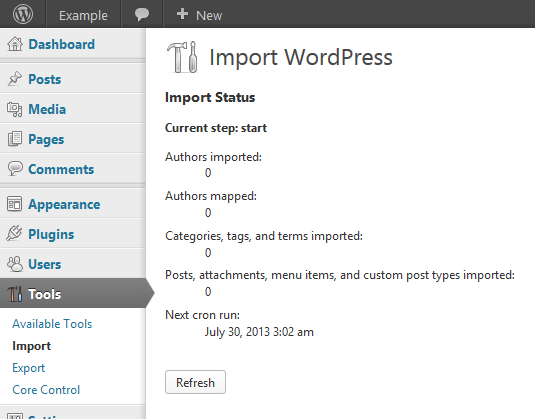
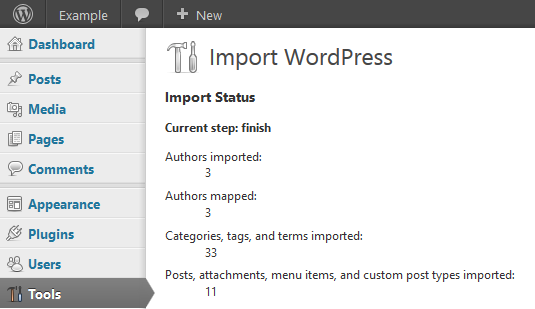
My project is to improve the migration experience and the portability of WordPress. Just the thought of moving WordPress elicits headaches because of all the things that can go wrong, as one stunningly recent discussion in the community reminded me.
For this project, I’ll be treading across both familiar and foreign territory. By current plans, I’d like to bring domain/URL A specific web address of a website or web page on the Internet, such as a website’s URL www.wordpress.org renames to the backend and WP CLI Command Line Interface. Terminal (Bash) in Mac, Command Prompt in Windows, or WP-CLI for WordPress., improve media handling and progress feedback in the WordPress-to-WordPress importer, and build in some semblance of plugin A plugin is a piece of software containing a group of functions that can be added to a WordPress website. They can extend functionality or add new features to your WordPress websites. WordPress plugins are written in the PHP programming language and integrate seamlessly with WordPress. These can be free in the WordPress.org Plugin Directory https://wordpress.org/plugins/ or can be cost-based plugin from a third-party. & option migration to the export/import workflow. (Subject to further change with notice.) More details will come in the days ahead.
I’m really thrilled to be working with all of you! In addition to my weekly updates here, my notes-to-self and handy links to Trac An open source project by Edgewall Software that serves as a bug tracker and project management tool for WordPress./source can be found on my project site. I’d love to hear your feedback here and throughout the project.
#migration-portability, #weekly-update



You must be logged in to post a comment.