Following last week’s update about the WP_Importer_Cron approach to writing importers and running import jobs, I’ve been steadily transitioning code from the current non-stateful, single-execution plugin A plugin is a piece of software containing a group of functions that can be added to a WordPress website. They can extend functionality or add new features to your WordPress websites. WordPress plugins are written in the PHP programming language and integrate seamlessly with WordPress. These can be free in the WordPress.org Plugin Directory https://wordpress.org/plugins/ or can be cost-based plugin from a third-party to a stateful, step-wise process (#327).
At the same time, I needed to separate presentation from logic/backend processing (#331) — something that @otto42 also recommended — in two ways:
- Removing direct
printf(), echo statements that were used by the WXR importer (example)
and changing them to WP_Error objects (example of fatal error; of non-fatal warning)
- Handling uploads and UI User interface choices in a separate class
Why must this be done now? Well, asynchronous tasks differ from PHP The web scripting language in which WordPress is primarily architected. WordPress requires PHP 5.6.20 or higher scripts directly responding to a browser request — we can’t depend on having access to submitted $_POST data, nor can we directly pipe output to the user. This change would also make it easier to understand what the code is doing from reading it, and to test programmatically.
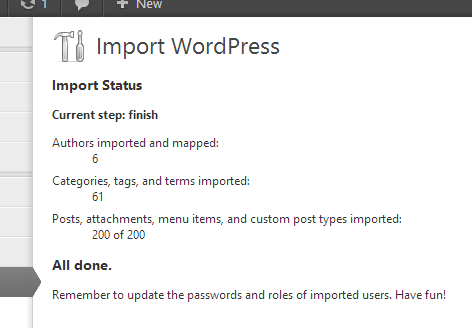
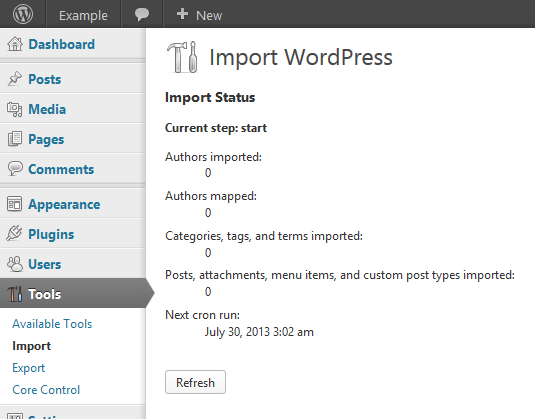
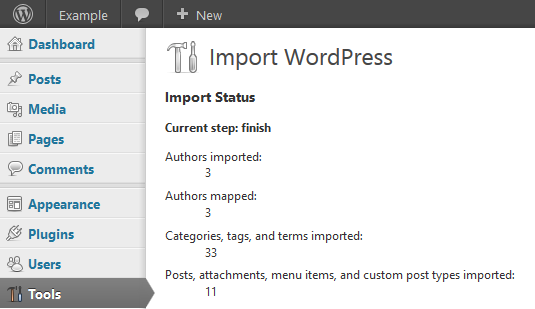
One dilemma I’ve encountered: how best to store the parsed import XML file. Since each step of the import (users, categories, plugins, etc) runs separately, we must…
- store all of the parsed data in variables, which are serialized into an option between runs
(obviously, a huge amount of data for which this may not be the most robust or efficient method);
- re-parse the XML on each run
(currently, parsers handle all parts of the XML at once, which means unnecessarily duplicated effort and time);
- modify the parsers to parse only part of the XML at a time; or
- split the XML file into chunks based on their contents (authors, categories, etc) and then feed only partial chunks to the parser at a time.
Any thoughts? Solving this problem could also help the plugin deal with large XML files that we used to need to break up by hand before importing. (The Tumblr importer doesn’t have the same problem because there is no massive amount of data being uploaded at the beginning.)
I haven’t yet finished transitioning all the steps; I’m afraid it won’t be possible to use this just yet. Before next Monday, I should have a downloadable plugin that’s safe to try.
#importers, #migration-portability, #weekly-update

You must be logged in to post a comment.